Exploratory Data Analysis to Understand Social Determinants Important to Global Neonatal Mortality Rate
This research project was conducted under my supervision at Rensselaer Polytechnic Institute (RPI), My student worked on this project under my guidlines and mentoring is: Joshua Chuah. This research project was a part of the Data Analytics course that I taught during Fall 2020 at Rensselaer Polytechnic Institute.
Outcome of this project was published as a conference paper in IEEE Big Data Conference ( IEEE BigData2020) in December 2020, (Virtual Conferece).
Download the conference paper here: Exploratory Data Analysis to Understand Social Determinants Important to Global Neonatal Mortality Rate
Project Overview
The Sustainable Development Goals (SDGs) are a set of targets that the UN hopes all countries will reach by 2030 broadly spanning the range of health, education, racial inequalities, environmental protections, and several other fields. Among these goals includes (Goal 3.2) an aim for all countries to reduce Neonatal Mortality Rates (NMR) to 12 per 1,000 live births. Without properly allocating resources to see the most dramatic shifts in NMR, many countries may be at risk of not meeting these ambitious goals. However, there are many factors which may influence national NMR, and while much previous work has been done to identify factors that influence NMR usually on a nation by nation basis, these factors can tend to vary. The goal of this study is to find factors that consistently lead, by changing them, to a change in NMR for many countries, in order to better inform health policy and resource allocations to the medical sector. This study will serve as an exploratory data analysis step for future studies regarding the impact of several health indicators on NMR per country. Cross-sectional data from the year 2014 were used for this Exploratory Data Analysis (EDA). To identify indicators that showed significant differences between the countries with high NMR and countries with low NMR, Mann-Whitney U Tests were performed. The p-value for each mean comparison was less than the 0.01 significance level. We have built a K-means clustering model to observe the variables’ contribution to NMR, as well as a K-means clustering model to observe the same data’s contributions to Gross Domestic Product (GDP), to see if both NMR and GDP follow similar trends across our target countries. The clustering for NMR groups of countries showed mostly separate clusters, while the clustering for the same data for the GDP classes showed very little separation, as the most points from each class all occupied the same cluster. To determine the actual amount that each indicator contributed to the data, Principle Component Analysis (PCA) was performed to understand the strongest contributions to the total data variance. The results of this study will serve to highlight the most important areas which must be improved in order to fulfill the Sustainable Development Goals (SDG) by the end of the next decade and to contribute to future studies that utilize longitudinal or more recent data.
Data Acquisition for the project
The data used for this study had three primary sources: the World Health Organization (WHO) Global Health observatory (ANC, IB, SHP) , the UNICEF Data Warehouse (NMR, WAT, SANI, LBW) , and the World Bank (GDP) . All data used for this study is publicly available.Exploratory Data Analytics
the primary purpose of these EDA are to identify target indicators for future studies among those suggested from literature. To determine differences, we first use the nonparametric Mann-Whitney U test to calculate the p-value comparing the means of individual indicators between countries of high and low NMR. In order to demonstrate separability of the data, we use K-Means Clustering to attempt to sort the data into two different categories based on their indicators, and PCA to measure the most relevant variables in explaining the NMR data.
Cluster Analysis
We use a combination of K-means clustering and Principal Component Analysis (PCA) to describe differences in the data for multiple indicators simultaneously. K-means clustering will divide the high-dimensional data into partitions described by a center point which is separate from all other center points . For the purpose of assessing the quality of the clustering, we are defining the clustering efficacy for K-means as the percentage of countries which were computed to be within a cluster where the majority of that group has been classified. This can be regarded as the amount of separation between the clusters, as we assume that greater separability in clusters (less overlap) implies that the trends in the data more accurately classify countries as higher or lower NMR. In this regard, complete separability would indicate that the factors used as dimensions are good estimators of the label groupings. K-means clustering was performed for the two groups of NMR: above and below the SDG threshold, as well as for the four GDP classes: lower, lower mid, upper mid, and upper. Principal Component Analysis was also performed on both clusters to explain the indicators which contribute to the largest share of variance in the NMR data, and to provide revealing visualization of the clusters which will be explored in the results section.
Clustering on Neonatal Mortality Rate (NMR)
The data for 31 countries was available for all 7 of the indicators we used. Indicators we explored are:
- Low Birth Weight (LBW)
- Sanitation (SANI)
- Access to basic water (WAT)
- Institutional Births (IB)
- Skilled Health Personnel at birth (SHP)
- Anteatal care Coverage (ANC)
- Gross Domestic Product (GDP)
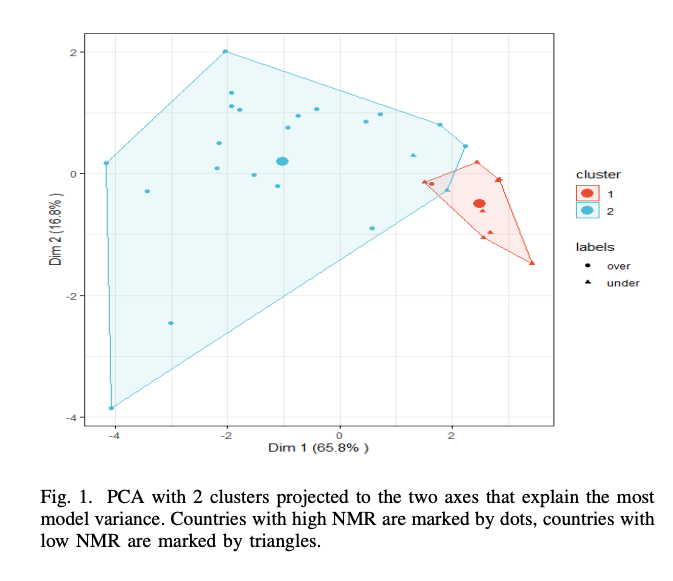
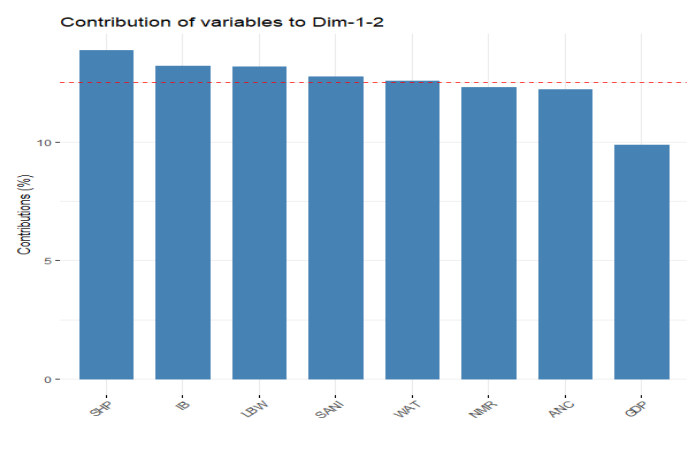
To determine the most relevant variables on the data, we performed PCA for the 7 indicators, resulting in as many principal components. Our first two principal components represent most of the data, accounting for a cumulative 83.4% of variance. Fig. 2 shows the contributions of the individual indicators to these important principal components, compared to the expected contribution. From this, we have 5 indicators with contributions above the expected for these components: Low Birth Weight (LBW), access to basic water (WAT), Sanitation (SANI), Institutional Births (IB), and Skilled Health Personnel at birth (SHP). A secondary clustering model was formed using these countries in order to determine if more data could potentially be included with minimal loss in clustering efficacy.
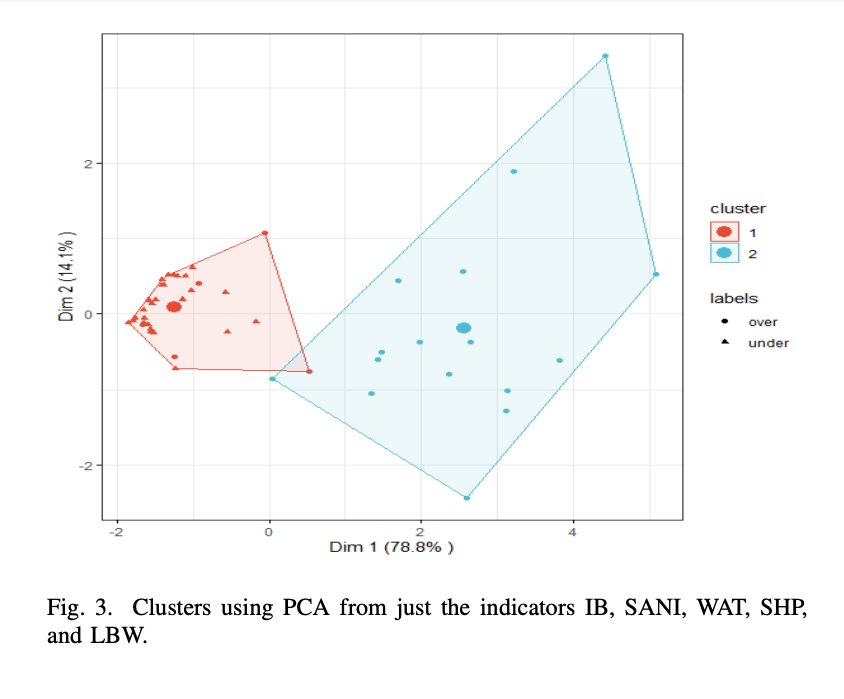
A secondary clustering model was formed using these countries in order to determine if more data could potentially be included with minimal loss in clustering efficacy. Data for the remaining 5 indicators was available for 49 countries: 21 of high NMR and 28 of low NMR. All 28 of the low NMR countries were clustered together, and 16 of the high NMR countries were in the other cluster, resulting in a clustering efficacy of 89.8%. For a relatively small decrease in efficacy, we are able to obtain data for 18 more countries with this simplified data model. Fig. 3. shows these clusters.
Clustering on Gross Domestic Product (GDP)
The same data for the same 49 countries was labelled again for GDP data, this time corresponding to the four GDP classes: low (less than $1,045 million) lower middle (between $1,045 and $4,125 million), upper middle (between $4,125 and $12,746 million) and upper (greater than $12,746 million). This clustering model showed that the majority of the countries for all 4 GDP classes were in the same cluster, resulting in a low clustering efficacy.
During the Exploratory Data Analysis (EDA) process using Principal Component Analysis (PCA), we have determined that the model containing the 5 indicators that contribute most to the principal components which have the highest cumulative proportion of variance for the model is not significantly worse than the model which uses the comprehensive data, while also allowing us to use data for 18 more countries: up to 49 from 31. We Fig. 1. PCA with 2 clusters projected to the two axes that explain the most model variance. Countries with high NMR are marked by dots, countries with low NMR are marked by triangles. Fig. 2. Bar plot showing the contributions of each indicator to the principal components which account for the greatest proportion of variance for the model. The red dotted line shows the expected contribution, which would be a uniform contribution from each indicator. Fig. 3. Clusters using PCA from just the indicators IB, SANI, WAT, SHP, and LBW. sacrifice 0.5% efficacy for a 58% increase in data. Using more countries in our analysis will not only enable greater certainty in the results but also demonstrates which indicators are most important for all countries to decrease NMR, as is the goal of this study. The good clustering separability for the NMR classes implies the NMR data for each country can be explained by the quantities of the indicators investigated.